プロセッサは微細化が進んだことにより, 高クロック化だけでは性能向上が望めなくなってきました。このため現在,さまざまな 単位での並列化によって,性能向上が追求されています。 たとえば命令単位での並列化であるスーパスケーラ,データ並列を生かすSIMD,スレッド並列を生かすマルチコア等です。
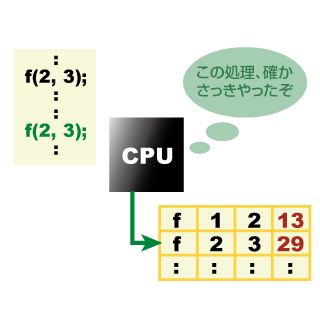
これらのアプローチはもちろん重要なものですが,並列化は,本質的に並列性を持ったプログラムしか高速化することができません。そこで我々は,並列化とは全く異なる概念である「メモ化」機能をプロセッサに持たせることで,高速化を実現する手法を提案しています。